สรุปจากการหัดเขียนภาษา R ผ่าน CodeSchool

บทความนี้เป็นการบันทึกการเรียนรู้พื้นฐาน R จากเว็บไซต์ tryr.codeschool.com/ หลังจากได้ยินชื่อภาษา R มานานละ แต่ไ่มรู้ว่ามันคืออะไร รู้แต่ว่ามันใช้งานในด้าน Big Data วิเคราะห์ข้อมูล ซึ่งปัจจุบันกำลังสนใจแนวๆนี้อยู่ได้ ด้านล่างก็เป็นสิ่งที่ได้เรียนรู้จากเว็บข้างบนนั่นแหละ ไม่ได้ติดตั้ง R ลงในเครื่องแต่อย่างใด เรียนผ่าน Website แบบคร่าวๆเท่านั้น ส่วน Compiler ก็เลยใช้ตัว R Compiler Online ที่ r-fiddle.org สะดวกดี ซึ่งทั้งหมดสรุปได้ดังนี้ อาจจะมีมั่วบ้างโปรดใช้วิจารณญาณในการอ่านเอาเองเด้อ
Ch 1 : R Syntax
- Expressions เหมือนกับภาษาอื่นๆ
- boolean ใช้คีย์เวิร์ด
TRUEและFALSE(ตัวพิมพ์ใหญ่ทั้งหมด) TRUEและFALSEเขียนแบบ short hand ได้ด้วยTและF- ประกาศตัวแปรและกำหนดค่าด้วยเครื่องหมาย
<-เช่นx <- 20สามารถ re-assign ได้ - ฟังค์ชัน ใช้คล้ายๆภาษาอื่น คือ ชื่อตามด้วยวงเล็บเปิด/ปิด เช่น
sum(4, 5, 6) help(functionname)และexample(functionname)เอาไว้เปิดอ่าน doc ช่วยชีวิต- รัน script ไฟล์ .R ด้วยคำสั่ง
source(filename)
Ch 2 : Vectors
- เก็บข้อมูล vector ใช้ syntax
c(1, 2, 3)(c ย่อมาจาก combine) - vector เก็บข้อมูลชนิดอะไรก็ได้
c('a', 'b', 'c')แต่ต้องเป็นชนิดเดียวกัน - vector ถ้าเก็บข้อมูลต่างชนิดกัน
c(1, TRUE, "three")ทั้งหมดจะถูกแปลงเป็น characters - sequence vector
5:9มีค่าเท่ากับseq(5, 9)ผลลัพธ์คือ5 6 7 8 9 seq()สามารถกำหนดค่าที่ต้องการจะ increase ได้seq(5, 9, 0.5)ผลลัพธ์คือ5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0- การ access ค่าที่อยู่ใน vector ใช้ index เหมือนกับภาษาอื่น แต่ต่างกันที่ ภาษา R เริ่มที่ index = 1
> sentence <- c('walk', 'the', 'plank')> sentence[3][1] "plank"> sentence[1][1] "walk"- access multiple ได้ เช่นเลือก index 1 และ 3
sentence[c(1, 3)] - สามารถตั้งชื่อ key ให้กับ vector ได้ด้วยฟังค์ชัน
names()ตัวอย่าง
ranks <- 1:3print(ranks)names(ranks) <- c("first", "second", "third")print(ranks)ผลลัพธ์
[1] 1 2 3 first second third 1 2 3- ฟังค์ชัน
barplotเอาไว้วาด Bar Graph จากค่า vectors ได้เลย (มี built-in ฟังค์ชันวาดกราฟมาด้วย เท่มาก)
data <- c(10, 7, 4, 13)barplot(data)
- ถ้าเกิดใส่
names()ให้กับ vector มันก็จะใช้ชื่อเป็น label ของ graph
data <- c(10, 7, 4, 13)names(data) <- c("First", "Two", "Three", "Four")barplot(data)
- การเพิ่มค่าให้กับ vector จะเพิ่มค่าให้ทุกตัวใน vector ด้วย เช่น
> a <- c(1, 2, 3)> a + 1[1] 2 3 4- บวกค่า vector 2 ตัวที่มีจำนวนเท่ากัน
a <- c(1, 2, 3)b <- c(5, 6, 7)print(a + b)
[1] 6 8 10- ในกรณีที่ จำนวนค่าใน vector ไม่เท่ากัน ลองทดสอบดูจาก r-fiddle มันจะก็อปค่า vector ที่สั้นกว่า ให้ยาวเท่ากับ vector อันยาว แล้วถึงทำ operator เช่น
a <- c(1, 2, 3)b <- c(2, 5, 3, 1, 2, 6, 7)print(a+b)
[1] 3 7 6 2 4 9 8ได้ผลลัพธ์เท่ากับ [1] 3 7 6 2 4 9 8 เพราะว่า มันจะกลายเป็น
a <- c(1, 2, 3, 1, 2, 3, 1)b <- c(2, 5, 3, 1, 2, 6, 7)- (ถ้า vector b ยาวมากๆ vector a ก็จะมีค่า 1, 2, 3, 1, 2, 3, … ไล่ไปเรื่อยๆ จนกว่าความยาวจะเท่ากับ vector b อันนี้ตามความเข้าใจจากการลองเล่นดูผ่าน r-fiddle ไม่รู้ถูกมั้ย :)
- เปรียบเทียบ vector ด้วย
==จะเป็นการเปรียบเทียบค่าแต่ละตัวใน vector - ฟังค์ชันสามารถรับ args เป็น vector ได้ เช่น
sqrt(c(2, 4, 16))หรือsin(c(2, 3, 4)) - ฟังชัน
plotรับ args เป็น vector 2 ตัว คือ ค่าแกน x และค่าแกน yplot(x, y) NAคือ Not Available หากบวกค่าด้วยNAจะได้ผลลัพธ์เป็นNAต้องกำหนดna.rm = TRUEซะก่อน
result = sum(c(2, 3, NA, 7), na.rm = TRUE)print(result)
[1] 12Ch 3 : Matrices
matrix(0, 3, 4)ทำการสร้าง matrix ขนาด 3 แถว 4 คอลัม ทั้งหมดมีค่าเป็น 0- สร้าง matrix จาก vector ด้วย
a <- 1:12m = matrix(a, 3, 4)> print(m)
[,1] [,2] [,3] [,4][1,] 1 4 7 10[2,] 2 5 8 11[3,] 3 6 9 12- สร้าง matrix ด้วยฟังค์ชัน
dim()โดยการรับ args เป็น vector และ assign ค่าเป็น vector ที่ระบุ แถวและคอลัม เช่น
plank <- 1:8dim(plank) <- c(2, 4)> print(plank)
[,1] [,2] [,3] [,4][1,] 1 3 5 7[2,] 2 4 6 8Ch 4 : Summary Statistics
mean()หาค่าเฉลี่ยของเซตข้อมูล เช่นmean(c(2, 3, 4, 5, 6))abline()เอาไว้สำหรับ draw line โดยรับ args เป็น h เช่น
data <- 1:4names(data) <- c("One", "Two", "Three", "Four")barplot(data)abline(h = mean(data))
median()คือการหาค่า median วิธีการหาค่า median คือ ทำการ sort ข้อมูลเรียงลำดับจากน้อยไปมากก่อน แล้วจากนั้นเลือกค่ากึ่งกลางมา ถ้าค่ากึ่งกลางมี 2 ค่าก็ให้เฉลี่ยจากค่า 2 ค่านั้นอีกทีหนึ่ง
data <- c(8, 3, 1, 9)print(median(data))
[1] 5.5Standard Deviationหรือ sd คือค่าเบี่ยงเบนมาตรฐาน เป็นการกระจายข้อมูลและแจกแจงความน่าจะเป็น คุ้นๆเหมือนเคยเรียนตอนสมัยมัธยม :) ส่วนวิธีการลืมหมดแล้ว
Ch 5 : Factors
factor()เป็นการรวมกลุ่มของ vector ให้เป็น unique โดยมีLevelsกำกับ- ค่าของ Levels ใน Factor ไม่ได้เป็น String แต่เป็น integer reference
chests <- c('gold', 'silver', 'gems', 'gold', 'gems')types <- factor(chests)
print(chests)print(types)
[1] "gold" "silver" "gems" "gold" "gems"[1] gold silver gems gold gemsLevels: gems gold silveras.integer()เอาไว้ใช้แสดง integer reference ของ factorlevels()แสดงเฉาพะ factor level- Plot graph ด้วยการใช้ 2 factors ก็ได้
weights <- c(300, 200, 100, 250, 150)prices <- c(9000, 5000, 12000, 7500, 18000)plot(weights, prices)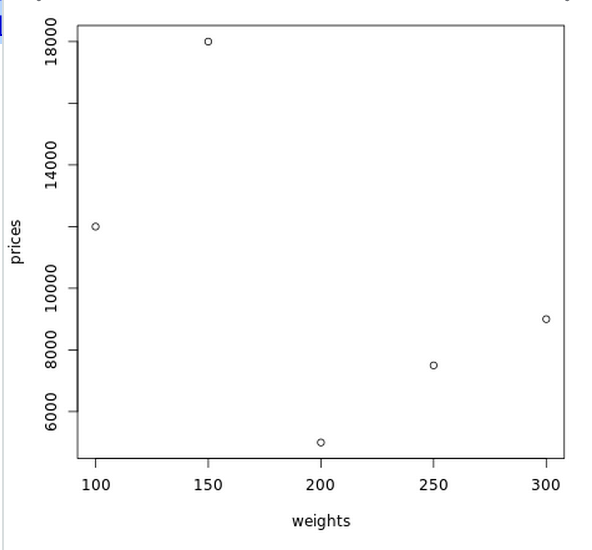 แต่ว่าจะดูไม่ออกว่าข้อมูลไหนคือ weights หรือ prices ถ้าหากมีข้อมูลเยอะๆ
แต่ว่าจะดูไม่ออกว่าข้อมูลไหนคือ weights หรือ prices ถ้าหากมีข้อมูลเยอะๆ
- ใช้
pchเป็น args เพื่อแสดงสัญลักษณ์ข้อมูลที่แตกต่างกัน (วงกลม, สามเหลี่ยม, บวก) legend()เอาไว้อธิบายเพิ่มเติมว่า แต่ละสัญลักษณ์มันคืออะไร เช่น แสดงที่บนขวามือของกราฟ
chests <- c('gold', 'silver', 'gems', 'gold', 'gems')types <- factor(chests)
weights <- c(300, 200, 100, 250, 150)prices <- c(9000, 5000, 12000, 7500, 18000)plot(weights, prices, pch=as.integer(types))
legend("topright", c("gems", "gold", "silver"), pch=1:3)เปลี่ยน legend() ที่เป็น hard code อยู่ เป็น
legend("topright", levels(types), pch=1:length(levels(types)))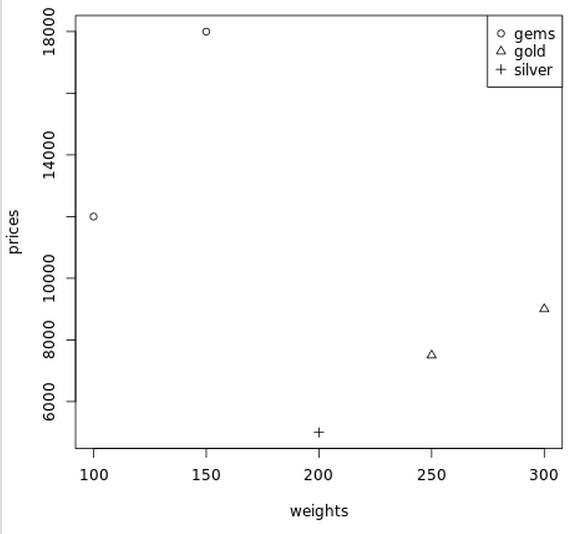
Ch 6 : Data Frames
- Data Frame ในภาษา R เปรียบเสมือนฐานข้อมูล เช่น ตัวอย่างอธิบายว่าหากเก็บข้อมูล
weights,pricesและtypesหากเพิ่มค่าใดค่าหนึ่ง ก็ต้องจำและเพิ่มมค่าอื่นๆตามด้วย จึงใช้ Data Frame เข้ามาช่วยรวมข้อมูลทั้ง 3 เป็น Data Structure ตัวเดียวกัน
จากข้อมูลด้านล่าง types, weights และ prices
chests <- c('gold', 'silver', 'gems', 'gold', 'gems')
types <- factor(chests)weights <- c(300, 200, 100, 250, 150)prices <- c(9000, 5000, 12000, 7500, 18000)เมื่อเก็บข้อมูลเป็น Data Frames จะเป็นแบบนี้
treasure <- data.frame(weights, prices, types)print(treasure)
weights prices types1 300 9000 gold2 200 5000 silver3 100 12000 gems4 250 7500 gold5 150 18000 gems- การ access data frame ทำเหมือนกันกับ matrix แต่ว่า ใช้
[[]](double brackets)
print(treasure[[2]])print(treasure[["weights"]])
[1] 9000 5000 12000 7500 18000[1] 300 200 100 250 150- ใช้
$เพื่อ access data frame โดยระบุชื่อของ data คล้ายๆกับ dot notation ของภาษาอื่นๆ
print(treasure$prices)
[1] 9000 5000 12000 7500 18000read.csv(filename)เอาไว้สำหรับโหลดไฟล์ .csv โดยชื่อไฟล์ ได้มาจากlist.files()- ข้อมูลที่ไม่ใช่ comma seperate แต่คั่นด้วยอย่างอื่น เช่น | หรือแท็ป จะใช้ฟังค์ชัน
read.table()โดยรับ args 2ตัว คือชื่อไฟล์ และsepสัญลักษณ์ที่ใช้คั่นข้อมูล
read.table('infantry.txt', sep = "\t")
V1 V21 Port Infantry2 Porto Bello 7003 Cartagena 5004 Panama City 15005 Havana 2000โดยจะมี Column Header V1, V2, … Vn แทรกมา วิธีการก็ต้องเพิ่มอีก args ลงไป
read.table("infantry.txt", sep="\t", header=TRUE)
Port Infantry1 Porto Bello 7002 Cartagena 5003 Panama City 15004 Havana 2000merge()ใช้สำหรับรวม Data Frame เข้าด้วยกัน โดยการรวม column ที่ชื่อเหมือนกัน
Ch 7 : Working With Real-World Data
- แสดงตัวอย่าง Real World Data โดยมีข้อมูล GDP ของแต่ละประเทศ และเปอเซนการใช้ซอฟแวร์ละเมิดลิขสิทธิ์ของแต่ละประเทศ เมื่อโหลดข้อมูลผ่าน
read.table()และทำการmerge()แล้วplot()กราฟออกมาได้เหมือนในรูป
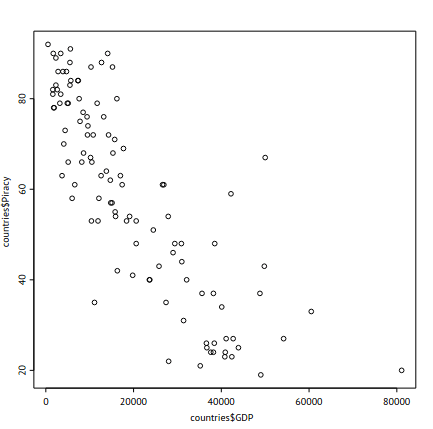
- จากกราฟแสดงว่าประเทศที่มี GDP สูง จะมีเปอร์เซนการใช้ซอฟแวร์เถื่อนต่ำ แต่ว่าข้อมูลแค่นี้จะเพียงพอต่อหรือไม่?
cor.test()เป็นฟังค์ชันที่เราไว้ทดสอบความสัมพันธ์ของ 2 vectors
cor.test(countries$GDP, countries$Piracy)
Pearson's product-moment correlation
data: countries$GDP and countries$Piracyt = -14.8371, df = 107, p-value < 2.2e-16alternative hypothesis: true correlation is not equal to 095 percent confidence interval: -0.8736179 -0.7475690sample estimates: cor-0.8203183-
ค่า
p-valueคือ Probability Value เหมือนเคยเรียนวิชา Probability คุ้นๆมากแต่ลืมว่ามันคืออะไร เอาเป็นว่าเป็นผลการทดสอบสมมติฐานหรือยอมรับสมมติฐาน ซึ่งในบทเรียนเค้าบอก ถ้าน้อยกว่า 0.05 แสดงว่ายอมรับในสมมติฐาน ซึ่งตามข้อมูล ก็คือ GDP มันแปรผกผันกับซอฟแวร์ละเมิดลิขสิทธิ์อยู่ -
lm()เป็นฟังค์ชันที่รับ args เป็น model formula คือรับค่า response variable (เปอเซนการละเมิดลิขสิทธิ์) กับpredictor variable(GDP) โดยมี~คั่นกลาง
line <- lm(countries$Piracy ~ countries$GDP)abline(line)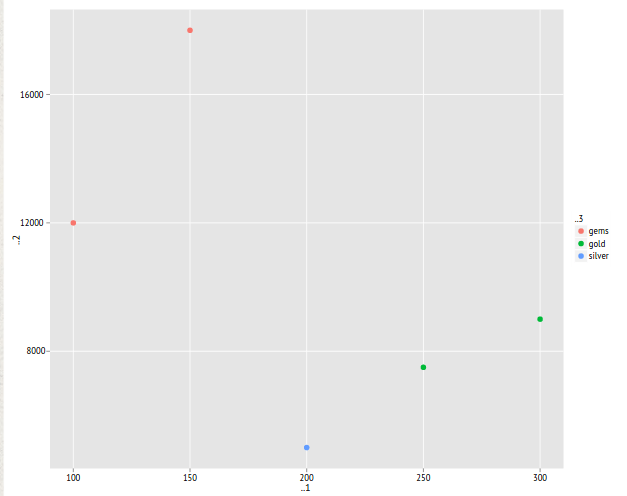
ggplot2เป็น graphic package ที่ช่วยให้กราฟดูสวยขึ้น- การติดตั้งและเรียกใช้ package ด้วย
install.packages("ggplot2") - ตัวอย่างเมื่อใช้
ggplot2
weights <- c(300, 200, 100, 250, 150)prices <- c(9000, 5000, 12000, 7500, 18000)chests <- c('gold', 'silver', 'gems', 'gold', 'gems')types <- factor(chests)
qplot(weights, prices, color = types)สรุป
หลังจากได้ทดลองเรียน R Language แล้วรู้สึกว่ามันเป็นภาษาที่เหมาะกับด้าน Data โดยตรงเลย นอกจากความรู้เรื่องโปรแกรมมิ่งแล้ว ยังต้องมีพวก Math มาเกี่ยวข้องด้วย ตอนที่ได้ลองอ่านก็ได้เจอศัพท์คุ้นๆที่เคยได้เรียน ได้ผ่านมาสมัยมัธยมปลายเพียบเลย คงต้องกลับไปทบทวนกันยกใหญ่เลยทีเดียว :)
- Authors
-

Chai Phonbopit
เป็น Web Dev ในบริษัทแห่งหนึ่ง ทำงานมา 10 ปีกว่าๆ ด้วยภาษาและเทคโนโลยี เช่น JavaScript, Node.js, React, Vue และปัจจุบันกำลังสนใจในเรื่องของ Blockchain และ Crypto กำลังหัดเรียนภาษา Rust